Adulteration detection of multi-species vegetable oils in camellia oil using Raman spectroscopy: Comparison of chemometrics and deep learning methods
基于拉曼光谱技术的山茶油中多种植物油的掺假检测:化学计量学方法与深度学习方法的比较
论文简介:
山茶油因其高含量的不饱和脂肪酸和功能成分而被视为高品质食用油,但由于价格较高,容易成为掺假目标。因此,开发一种快速、准确且易于操作的掺假检测方法对于保障山茶油市场的健康发展至关重要。拉曼光谱技术因其高分辨率和对水分子干扰小的特点,已被成功应用于食用油掺假检测。本文研究了利用拉曼光谱技术结合传统化学计量学和深度学习方法检测山茶油(Camellia Oil, CAO)中掺杂多种食用油的掺假行为。研究旨在通过统计比较,评估这两种方法在识别和定量分析掺假山茶油中的优势,为食用油掺假检测提供新的技术手段。
本研究选取了六种常见的食用油(大豆油、菜籽油、玉米油、红花油、花生油和山茶油)油以不同比例(1%到100%)掺入山茶油中,制备了300个掺假样本。在分类阶段,研究使用了线性判别分析(LDA)、支持向量机(SVM)、随机森林(RF)等传统化学计量学方法,以及长短期记忆网络(LSTM)、卷积长短期记忆网(ConvLSTM)和Transformer等深度学习方法构建分类器。在定量预测阶段,使用偏最小二乘法(PLS)及其变量选择改进方法(VIP-PLS、CARS-PLS、Random Frog-PLS)和深度学习模型(LSTM、ConvLSTM、Transformer)对掺假水平进行预测。结果显示,传统化学计量学和深度学习方法在定性识别掺假山茶油方面均表现出高准确率(100%),但在低掺假水平(1%和5%)下存在部分误分类。深度学习方法在分类性能上略优于传统方法,尤其是在ConvLSTM模型中,其AUC值在不同掺假水平下均高于其他模型。在定量预测掺假水平方面,深度学习模型显著优于传统化学计量学方法。最优ConvLSTM模型在预测集上实现了R²P = 0.999、RMSEP = 0.9%和RPD = 31.5的性能,表明其对低掺假水平的预测能力极强。相比之下,传统化学计量学方法(如VIP-PLS)的RPD仅为4.7,预测误差较大。
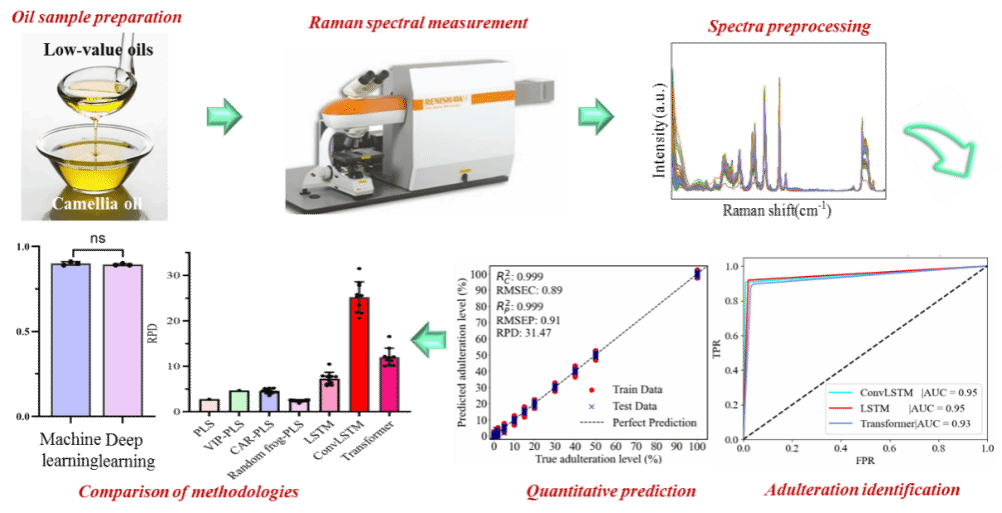
图1 图摘要
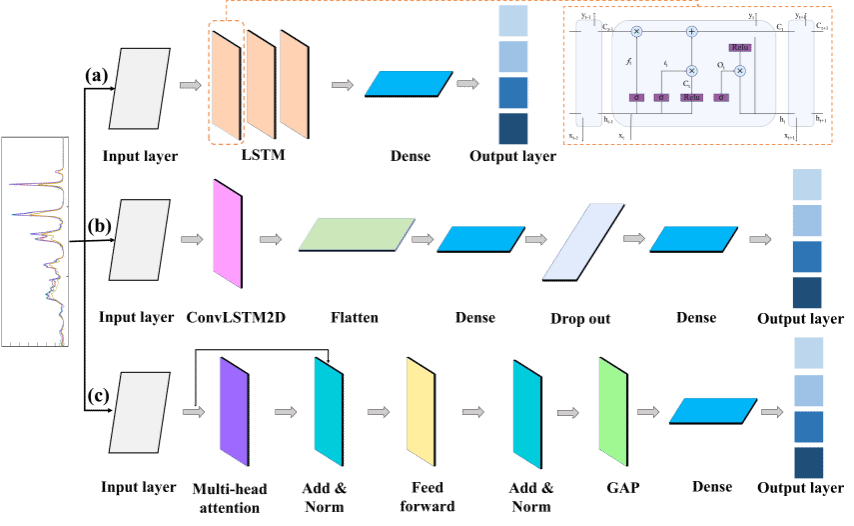
图2 深度学习网络结构

图3 化学计量学与深度学习模型在CAO掺伪定性与定量分析中的比较
综上所述,拉曼光谱结合深度学习方法在山茶油掺假检测中具有显著优势,尤其是在定量预测掺假水平方面。深度学习模型能够有效处理复杂的光谱数据,并为不同掺假油的全球模型开发提供支持。该研究为复杂食品掺假检测提供了新的思路,并为其他食用油掺假检测提供了参考。
该研究成果于2024年9月16日发表于国际知名期刊“Food Chemistry”。食品学院王加华副教授为第一作者,刘小丹博士为通讯作者,2022级硕士研究生钱奖金完成了主要工作。
文章链接:https://doi.org/10.1016/j.foodchem.2024.141314